Introduction
ICIL对第九届全国大学生集成电路创新创业大赛的赛题分析
竞业达赛题分析
赛题任务
在FPGA上设计和实现一款基于RISC-V指令集的CPU,完成若干工业应用程序和操作系统的性能测评。
http://univ.ciciec.com/nd.jsp?id=879#_jcp=1 (赛题链接)
题目解读
关键词: CPU RISC-V FPGA 工业应用程序 操作系统
1、CPU 和 RISC-V架构是什么?
CPU 全称为 "Central Processing Unit" 即 中央处理单元,也就是我们最常泛指的处理器是目前应用最广泛的数字芯片之一。
RISC-V 架构全称为"Reduced Instruction Set Computer V",是第五代精简指令集的简称,是目前最火热的开源精简指令集架构之一。
那么两者是怎么联系起来的呢? 这就不得不提到CPU的工作流程,CPU的工作实际上就是在执行一条一条的指令。需要执行指令,那么就需要有指令规范,也就是指令集。而RISC-V则是诸多指令集的一种。指令集主要分为CISC架构(复杂指令集架构)和RISC架构(精简指令集架构)两种。 复杂指令集的指令功能强大,但实现复杂,电路面积功耗开销大,常用于桌面端或服务器。例如英特尔的酷睿系列,AMD的R系列CPU都是复杂指令集架构(X86/X64)。精简指令集相对简单,电路实现也没有那么复杂,常用于移动端。像是苹果的A系列以及华为的麒麟系列都用的是精简指令集(ARM)。
2、工业应用程序和操作系统的性能测评指什么?
工业应用程序其实就是一些依托简单CPU就能运行起来的小程序,在这里可以充当一个testbench的功能,用来测试你的CPU是否能正常执行功能。
操作系统即我们常说的OS,现代高性能CPU往往不是裸机运行,而是依托操作系统以完成交互。我们所常说的 ios 安卓 windows都是常见的操作系统。而这里的操作系统特指RTthread,一种流行的开源嵌入式操作系统。RTT官网传送门。
3、如何在在FPGA上完成设计?
FPGA全称"Field Progammable Gate Array"即现场可编程门阵列,通过HDL语言就可以在FPGA上模拟出你设计的CPU。
设计指标(基础)
- RISC-V CPU需要在组委会提供的实验箱上进行设计和实现;
简单来说就是要把设计的CPU移植到企业提供的平台上,企业会提供一个实验箱(线上),预计可能包含类似于NVboard的虚拟FPGA,并提供OS移植相关的手册,具体内容要等实验箱资料发放,或者蹲问答群应该会有人问。
- 支持RISC-V RV32I指令集;
RV32I是RISC-V指令集中的一部分。I指的是整数指令。也就是说只需要赛题只需要实现RISC-V的整数指令就行了,大概是30多条吧;32是指32位架构,意味着CPU的架构寄存器是32个,指令长度和寄存器大小也是32位。
- 完成官方提供的若干工业应用程序的性能测评;
该程序由官方提供,且应该在官方的实验箱环境中可以运行起来。大概率只是简单验证RV32I指令的一些程序,实际上ysyx里就有不少这样的测试样例。
- 完成RT-Thread的性能测评;
正常来说仅仅依靠RV32I是无法启动RT-Thead的,因为一个基本的OS需要完成批处理和异常处理两个基本职能。而这两个职能需要用到CSR指令,也就是说除了RV32I,要是想启动RTT还需要完成一部分的CSR工作。并且需要完成RTT官方的一些API,以支持基本的上下文切换等功能。这一工作是为了适配OS和CPU,有一个专有的说法叫BSP,全称是 "Board Support Package"即板级支持包。
设计指标(进阶)
-
通过流水线、Cache、指令并行等多种方式优化CPU性能;
该项主要是对CPU的性能进行优化,包括流水线技术,多级发射技术,乱序执行技术,分支预测技术,Cache技术,数据预取技术等,在此不细展开。 相关书籍推荐:《计算机组成原理》《超标量处理器设计》 速成传送门:流水线,Cache,分支预测,乱序执行
-
添加并支持浮点运算单元;
浮点型即float型,与C语言中的float是类似的概念,完成FPU(浮点运算单元)即可支持RV32F指令。来自东南大学参赛队伍的RV32 FPU设计。
-
添加并支持AXI总线;
AXI是一种总线家族,常用于CPU与主存、缓存之间的交互。其本质上是基于简单握手协议的复杂实现。AXI家族有很多总线类型,如AXI-3,AXI-4,AXI-lite等。
评分机制
具体材料见官网要求,在此只做分析总结
初赛
总结实际上要求很低,不需要跑通应用程序,也不需要启动RTT,更不需要支持除了RV32I以外的其他功能。也就是说,哪怕是做一个简单的单周期,然后去ysyx找测试用例跑通工作量都够了。当然报告和视频要做好。
分区决赛
分区决赛最大的不同是要现场跑测试程序并跑通,但是计时机制不明朗。预计有可能是测试箱内置的测时标准,如果是手机的话电脑影响因素很大,如果是自己在tb里计时计算方式难以统一。在初赛做出流水线会有很大优势。
全国总决赛
比起复赛有两个不同,一是需要现场运行RT-Thread操作系统,二是需要考核进阶的设计指标。也就是说RTT已经是决赛要求了(但是其实单周期都能启动RTT)。而且进阶指标只需要完成两个就是满分了,实际上很简单。
学习路线
只需要三步,就可以拿到一个国奖 ^^_^^
第一步,推荐学习《计算机组成原理》,以及Verilog程序设计。完成学习后,尝试设计一个RV32I单周期CPU,互联网上已经很多相关的教程。 第二步, 在完成单周期设计后,对一些测试用例进行测试,顺利通过之后尝试官方的应用程序,成功通过官方的应用程序后,尝试启动RT-Thread操作系统。 第三步,在完成以上内容后,你已经成功入门CPU设计。继续尝试设计流水线、Cache等更为复杂的结构,拿满决赛的两项附加分。
中科芯杯赛题分析
赛题任务
设计一个TPU(Tensor Processing Unit),并且在FPGA上进行验证。
http://univ.ciciec.com/nd.jsp?id=886#_jcp=1 (赛题链接)
题目解读
关键词: TPU AXI FPGA
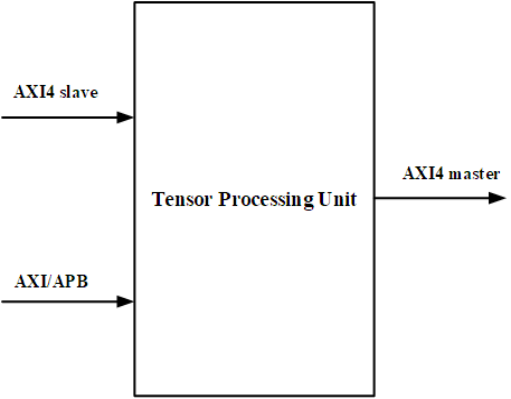
通过上图,我们可以很清晰地看到我们需要设计的模块。其中输入有AXI4 slave,AXI/APB;输出有AXI master。还有中间进行计算的TPU。
TPU
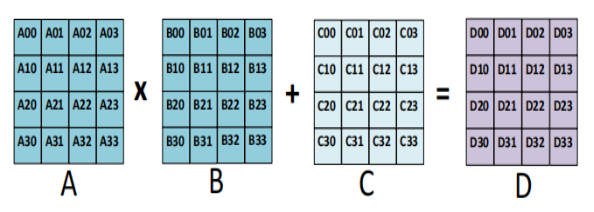
我们要设计的TPU需要实现矩阵乘加计算,支持INT4、INT8、FP16、FP32四种数据精度,支持混合精度计算。并且要对不同精度的乘法运算有硬件资源复用设计(举个例子:一个16位宽的支持 INT8 和 INT16 的乘法单元,那么做INT8运算时,前8位全是0)。可以参考谷歌的TPU设计以及AIC2021 Project1实现了一个简单的TPU。
总线
总线是用来传输数据的,比如你手机通过数据线传输数据到电脑,那么你的数据线就是总线。有了总线,就得定义手机跟电脑应该怎么沟通,手机是发送数据给电脑,还是电脑发射数据给手机,该发送什么数据,这些就是总线协议定义的。 我们一般称主动发起通信的模块为master(主设备), 称响应通信的模块为slave(从设备)。外部模块,比如CPU作为master,发送要计算的矩阵到TPU的AXI4 slave, 并且通过AXI/APB配置TPU的寄存器。TPU完成计算之后,通过AXI4 master将计算完成的数据发送出去。我们所要设计的模块,要求使用的协议是AXI4-full与APB。前者用于读取与写回矩阵数据。后者用来配置寄存器(可能用于指定要进行的计算类型,题目中指定由参赛队伍自行定义)。
FPGA验证
FPGA验证在题目中是附加分,但是要完成还是比较简单。 这里提供一个简单的验证方案。电脑通过串口将矩阵发送到FPGA,FPGA接收完成数据之后,写一个模块,将要计算矩阵数据写入你设计的TPU,计算完成后,写一个模块,该模块接收TPU的AXI4 master发来的数据,再通过串口写回电脑。 电脑接收完成数据,可以再通过python或其他软件去计算发送过去的矩阵,验证接收到的计算结果是否跟电脑的计算结果相同。
设计指标(基础分)
- 实现要求的功能
m16n16k16、m32n8k16、m8n32k16的矩阵乘加运算,INT4、INT8、FP16、FP32数据格式,混合精度计算模式,支持计算结果溢出的情况。
- 硬件资源复用方案
- 设计的综合频率、面积、功耗、理论算力值等
对于设计的频率,可以查看FPGA给出的时序分析。或者使用yosys-sta跑出来的频率与面积。
设计指标(附加分)
- FPGA验证
前文已经提到了一个简单的方案。
- 数据精度混合计算模式扩展
例如在FP16 Mixed Precision模式下,以FP16数据精度进行乘法运算,以FP32数据精度进行累加运算
- 稀疏张量计算扩展
评分机制
初赛,分赛区决赛,全国总决赛要求基本相同。但在初赛阶段不考察加分项内容;分区决赛阶段的评分仅加入一项加分项的考察评分;总决赛阶段的评分可加入两项加分项的考察评分。
开发环境
介绍两种开发环境
FPGA
可以使用Vivado,方便后续直接进行FPGA验证。使用SystemVerilog进行仿真。支持Windows和Linux。缺点就是Vivado下载完占用超过了100G
Verilator
使用vscode,Verilator,gtkwave/suffer在Linux下进行开发。仿真可以使用C++,比较灵活。占用存储空间极小。缺点是Linux学习成本高,并且做FPGA验证时还是得用Vivado。
参考资料
-
脉动阵列
这是用来计算矩阵乘法一个架构,也是Google TPU和AIC2021 Project1中采用的。里面的参考文献也推荐阅读。 -
An in-depth look at Google’s first Tensor Processing Unit (TPU)
-
In-Datacenter Performance Analysis of a Tensor Processing Unit
学习路线
- 学习数电与Verilog以及Verilog的仿真
- 总线协议,学习怎么跟你的TPU沟通。可以查看参考资料中的两个初步了解(实现总线协议需要阅读对应协议的手册)。
- 你需要点数学基础,包括线性代数。
- 学习TPU的架构,脉动阵列;最后动手写出你的第一个TPU。
龙芯中科赛题分析
赛题概括
利用杯赛企业提供的或自行设计的IP,构建一个基于LoongArch指令集的芯片设计并在FPGA平台上完成原型系统验证,并完成针对芯片电路模块的集成电路后端设计实践。
http://univ.ciciec.com/nd.jsp?id=882#_jcp=1(赛题链接)
赛题任务及解读
初赛
利用杯赛企业提供的IP和芯片设计指导,构建一个基于LoongArch指令集的芯片设计并在FPGA平台上运行指定软件完成测试,提交设计文档。
1、IP是什么?
IP 是 Intellectual Property(知识产权)的缩写,在电子与计算机领域通常指的是某个特定的设计或技术方案,其拥有法律保护。IP可以指硬件设计、软件算法、协议标准等内容。在集成电路(IC)设计中,IP的使用可以大大加速开发周期,因为它们是可以直接集成到芯片设计中的现成模块,不需要重新开发。比如,可以直接使用已经设计好的处理器IP,直接将其嵌入到自己的芯片中,这样就能专注于其他特性和优化。
杯赛企业提供的IP资源包含支持LoongArch架构的处理器核、片上互连总线和部分外设接口,其中处理器核IP包括LA132(教育版)和OpenLA500。LA132(教育版)需要参赛队所在学校与龙芯中科公司另行签署免费授权协议后定向发布。
2、LoongArch指令集。
LoongArch指令集 LoongArch指令集(龙架指令集)是中国自主研发的指令集架构(ISA),LoongArch是基于RISC(Reduced Instruction Set Computer,简化指令集计算机)架构设计的,它的指令集相对简单,操作较为直接,能够高效执行基本运算操作。目标是替代国际通用的X86和ARM架构,推进国内芯片自主可控的发展。
3、FPGA
FPGA(现场可编程门阵列)是一种硬件描述语言(HDL)编程的可编程芯片。通过FPGA验证,可以在设计初期对芯片进行原型验证,减少错误并加速芯片的迭代优化。对于本赛题,FPGA平台将作为芯片设计的验证环境:
- 设计原型:使用FPGA开发板进行芯片的原型开发,确保指令集与硬件协同工作。
- 功能测试:在FPGA上加载测试程序,验证芯片的基本功能,确保设计正确无误。
- 性能验证:在FPGA上执行性能评估,检查芯片的运算速度、能效等性能指标。
初赛阶段各参赛队限定使用“计算机系统能力培养远程教学平台”远程FPGA实验平台,杯赛企业将在整个竞赛期间向杯赛参赛队免费提供远程FPGA实验平台账号。
分区赛
各参赛队可以在初级赛阶段完成内容基础上,通过自主设计IP等方式对芯片进行功能扩展和性能优化;同时各参赛队基于集成电路后端设计参考流程完成给定电路模块的后端设计并形成实践报告;最终提交设计文档与数据并进行现场答辩演示。
1、功能扩展和性能优化。
前端设计不仅要在FPGA平台上通过功能测试程序集还需要通过系统测试程序集。
2、后端设计。
后端设计是集成电路设计的一个关键环节,它主要包括以下几个步骤:
- 布局和布线:在芯片设计中,后端设计的第一步是根据电路图进行物理布局,将各个组件放置在合适的位置,并进行布线,使得信号和电源能够正确传输。
- 时序分析:检查电路的时序是否满足要求,确保数据在正确的时间传输,并且不会出现信号延迟或冲突。
- 功耗分析:评估芯片的功耗,特别是在高频工作时,优化功耗以确保芯片高效运行。
- 验证和优化:进行功能和时序验证,确保电路模块的设计符合预期要求。之后,进行必要的优化以提升性能。
3、进阶
自主设计IP并在芯片中集成应用;对集成自主设计IP的芯片设计完成后端设计,形成正确输出;
国赛
国赛评比的内容跟分区赛是一样的,所以只要把分区赛继续做好就行啦。
学习路线
1、处理器架构 & LoongArch 指令集
- 掌握 LoongArch 指令集的基本操作(寄存器、访存、分支等)。
- 熟悉 LoongArch 现有开源处理器(OpenLA500、LA132)结构。
推荐资料《计算机组成原理》、LoongArch 官方 ISA 手册。
2、FPGA 开发基础
掌握 Verilog语言、熟悉FPGA使用。
3、IC 后端设计
叩特杯赛题分析
赛题任务
USB2.0协议的数据链路层模块设计。
http://univ.ciciec.com/nd.jsp?id=884#_jcp=1 (赛题链接)
题目解读
关键词: USB2.0 前后端
USB2.0简介
USB 2.0(Universal Serial Bus 2.0)是一种广泛应用的高速串行总线标准。这里只简单的介绍USB2.0
物理层
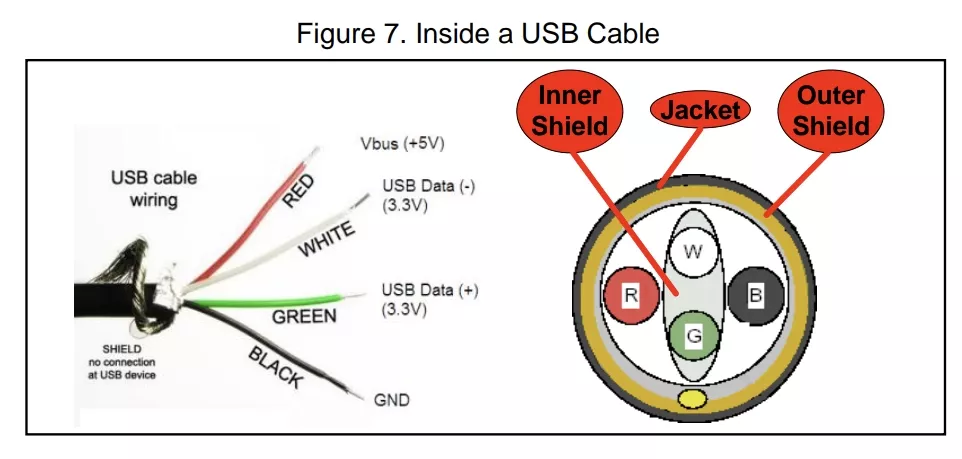

USB 2.0 使用 四根线,分别为:
- VBUS(+5V):供电线,为设备提供电源。
- GND(地线):电源地线。
- D+ 和 D-(数据线):差分信号对,用于数据传输
链路层
USB 接口需要两个主要硬件模块:收发器(也称为 PHY,物理层的缩写)和串行接口引擎(也称为 SIE)。收发器提供 USB 连接器与控制USB 通信的芯片电路之间的硬件接口。SIE 是 USB 硬件的核心。它执行多种功能,如 USB 数据的解码和编码、纠错、位填充和信令。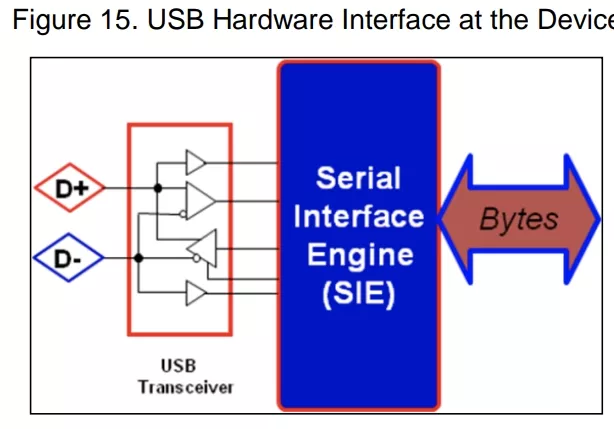
物理层接收到了数据,会给到数据链路层去做一些纠错,解码的操作,我们设计的模块就类似于SIE。仔细阅读USB2.0的手册,其中关于通讯协议的部分解释了你具体需要实现的功能,,需要详细阅读。
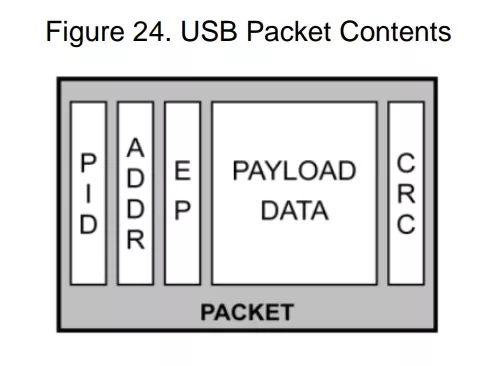
-
数据包标识(PID) – (8 位:4 位类型位 + 4 位错误校验位)。这些位用于声明事务类型,如 IN/OUT/SETUP/SOF。
-
可选设备地址(ADDR) – (7 位:最多支持 127 个设备)。
-
可选端点地址(EP) – (4 位:最多支持 16 个端点)。USB 规范支持最多 32 个端点。虽然 4 位的端点地址最大值是 16,但通过 IN PID 和端点地址(1 到 16)以及 OUT PID 和端点地址(1 到 16),可实现总共 32 个端点。请注意,这里指的是端点地址,而不是端点编号。
-
可选有效载荷数据(PAYLOAD DATA) – (0 到 1023 字节)。
-
可选 CRC 校验 – (5 位或 16 位)。
前端
工具
叩特在比赛中会提供服务器和比赛需要用到的后端软件:VCS、Verdi、Design Compiler,Prime Time。
VCS:HDL仿真
Verdi:加载波形文件,查看信号的波形及其对应的代码来进行调试
Design Compiler:生成网表
Prime Time:STA(时序分析)
后端
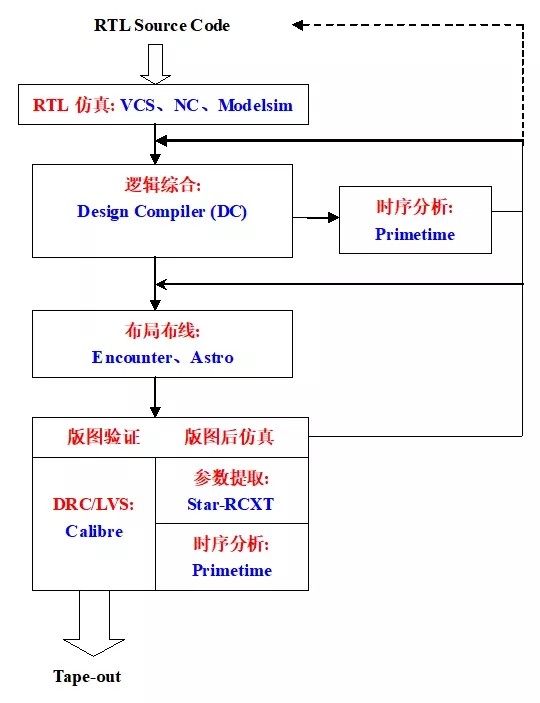
在设计及仿真自测流程完毕的基础上,后端flow完成基于Innovus的APR环境搭建,完成设计初始化并检查网表、时序等,完成FloorPlan阶段对芯片面积规划以及IO port的摆放,完成时钟树单元及NDR绕线规则的指定、配置CTS相关参数及设置,配置Route相关option及参数并完成最终绕线,完成postRoute阶段的优化工作,完成PR之后的STA相关工作。要求完成后端基本流程实现,并经过多次优化,输出netlist、def和lib等文件。
名词解释
Innovus:软件;后端流程中,Innovus用于完成从网表到最终布局的所有物理设计步骤,包括FloorPlan、Place、Route、Optimization等
APR环境:Automated Physical Design,自动化物理设计。用于自动化完成芯片物理设计的流程,包括布局、绕线、时钟树合成等
FloorPlan阶段:FloorPlan是物理设计的第一步,主要用于规划芯片的面积、形状、模块布局以及I/O端口的位置。
时钟树单元:时钟树单元是用于生成和优化时钟网络的模块
NDR绕线规则:Non-Default Routing(非默认绕线)规则。NDR规则用于定义特殊的绕线需求
CTS:Clock Tree Synthesis(时钟树合成)。用于自动生成和优化时钟树网络的过程
Route:Route是指在物理设计中为网表中各个模块之间的连接分配具体的物理路径的过程
postRoute阶段:postRoute阶段是指绕线完成后,对设计进行的优化和检查,包括时序优化、信号完整性分析等
PR:Physical Design(物理设计)。PR是指将前端设计的网表转化为物理布局的过程,包括FloorPlan、Place、Route等步骤
STA:Static Timing Analysis(静态时序分析)。分析芯片中所有时序路径的延迟,确保设计满足时序要求
netlist:Netlist是描述数字电路中模块之间连接关系的文件,通常由前端设计工具生成
def:DEF文件是用于描述芯片物理布局的标准格式文件,包含模块的位置、绕线信息等。DEF文件是后端设计的输出文件之一,用于记录最终的物理布局结果。
lib:Lib文件包含了标准细胞的功能、时序和功耗信息,是前端设计和后端设计的重要输入文件。Lib文件为后端设计提供了标准细胞的物理和时序模型,用于实现物理设计和时序分析。
工具
叩特在比赛中会提供服务器和比赛需要用到的后端软件:Prime Time、StartRc、Formality、innovus。
Prime Time: 静态时序分析(STA)
StartRc:寄生参数提取
Formality:形式验证工具
Innovus:布局、绕线、时钟树合成和优化
设计指标/评分机制
初赛
仅看RTL代码以及仿真
分赛区决赛
仿真以及输出网表文件
全国总决赛
完成后端流程
开发环境
仿真fsdb文件(波形),TSMC 65nm工艺库相关文件;EDA工具:VCS、Verdi、Design Compiler、Prime Time、StartRc、Formality、innovus
参考资料
USB 101: An Introduction to Universal Serial Bus 2.0
USB 2.0 Specification(你应该只需要阅读其中的usb_20.pdf)
学习路线
-
HDL语言(verilog)与数电
-
USB2.0的手册
-
前端设计的各种工具软件(通过VCS仿真,Prime Time进行STA)
-
后端设计的各种工具软件
曾益慧创杯赛题分析
赛题任务
555定时器芯片的的设计验证和测试(模拟IC设计、验证、测试)
http://univ.ciciec.com/nd.jsp?id=890#_jcp=1 (赛题链接)
题目解读
关键词:555定时器 EDA工具
1、 555定时器
555定时器是一种多用途的,集数字、模拟于一体的8引脚时基集成电路,其应用极为广泛。它不仅用于信号的产生和变换,还常用于控制和检测电路中。由于使用灵活、方便,故而在波形的产生与交换、测量与控制、家用电器、电子玩具等许多领域中都得到了广泛应用。可在双稳态模式(施密特触发器)、单稳态模式、无稳态模式(多谐振荡器) 三种模式下工作。内部结构一般由分压电路、比较器电路、锁存器电路、触发器电路等组合而成,具体电路结构根据设计指标和要求而改变。
2、EDA工具
EDA(电子设计自动化)工具 是指利用计算机辅助设计来完成集成电路芯片功能设计、综合、验证、物理设计(包括布局、布线、版图、设计规则检查等)等流程的设计工具,涵盖了电子设计、仿真、验证、制造全过程的所有技术。不同的 EDA工具 功能侧重点不同,需要根据实际选择。 完成555定时器模拟IC设计需要的EDA(推荐)
- Cadence Virtuoso
adence Virtuoso 是一款专业的集成电路设计工具,提供了从电路设计、仿真到版图设计的全流程解决方案。。对于 555 定时器这类 IC 电路的设计,它可以进行精确的电路级和版图级设计。
- Synopsys HSPICE
HSPICE 是一款业界标准的电路仿真工具,它支持多种仿真模式,能对复杂的模拟电路进行详细的性能分析。在 555 定时器 IC 电路设计中,它可以帮助你准确预测电路的行为和性能。
设计指标(基础)
- 完成555定时器芯片的电路和版图设计工作,包括设计阶段的前仿和后仿验证工作
根据杯赛给出的功能要求、性能指标使用0.18μm工艺进行设计。在保证满足芯片功能指标的同时需要注重设计的完整性,并通过DRC、LVS验证,以设计出能达到要求的的芯片为首要条件,后期再进行优化。需要注意在原理图设计时指标要求留出一定余量,避免版图寄生参数提取后的后仿真不通过。
设计指标(优化)
- 创新性:电路架构和算法是否有创新
- 后仿真结果分析及优化
- 满足技术指标下,面积和功耗越小越好
评分机制
具体材料见官网要求,在此只做分析总结
初赛
需要设计出一个555定时器芯片,关键在于保证原理图、版图设计、前仿真和后仿真的数据完整,电路架构设计以合理且满足性能指标优先,在保证自身能力足够的前提下再考虑复杂的电路结构,避免在后期优化困难。
分区决赛
本杯赛的分区决赛采用现场硬件搭建、测试的形式,简单地说在初赛阶段的设计成果并不会用到分区决赛中,在本阶段需要完成电路板卡上空缺元器件的测试选型,并对整个电路完成现场要求的测试工作,需要更深入且全面了解555定时器芯片的结构和性能。
全国总决赛
本阶段同样采用现场测试、开发的形式进行,完成555定时器芯片量产测试程序开发,实现芯片的自动化测试,需要注意的是测试软件框架基于LabVIEW实现。
LabVIEW是一款图形化编程语言,芯片自动化测试中应用非常广泛,网上有很多开源教程。
参考资料
555定时器原理及应用 555定时器工作原理与常见应用 模拟IC设计全流程 EDA软件工具推荐
学习路线
- 学习模电、数电、电路设计、版图设计,555定时器芯片属于集成块,涉及知识较广,只需要重点学习相关部分,否则时间成本太高。
- 选择一个EDA工具,大部分功能较完善且操作友好的EDA软件(如Cadence, Synopsys, Mentor等)一般都需要在Linux系统下操作,具体选择根据实际进行。
- 完成基础理论学习后,先架构芯片电路整体框架,在电路搭建完成后进行前仿真,根据进行结构和参数调整;在进行版图设计时要重点关注版图布局布线是否合理,同时尽量减小寄生参数,完成后进行DRC和LVS验证,通过后提取寄生参数进行后仿真,根据指标要求不断迭代修改。
法动杯赛题分析
赛题任务
基于法动科技EDA工具(EMOptimizer®、UltraEM®、FDSPICE®),设计一款Sub-6GHz 5G宽带射频芯片模组
http://univ.ciciec.com/nd.jsp?id=875#_jcp=1 (赛题链接)
题目解读
关键词: Sub-6GHz 5G 射频芯片模组 AI优化 电磁仿真 IPD工艺
1、Sub-6GHz 5G宽带射频芯片模组是什么?
Sub - 6GHz 5G 宽带射频芯片是一种用于 5G 通信系统的关键芯片,主要用于高速通信。而“Sub - 6GHz” 是指其工作频段在 6 GHz以下的频率范围。该芯片可以用于发射或接收信号,而其发射和接收过程需要进行复杂地信号调制,功率放大等步骤,这便是设计该芯片的难点。
2、射频芯片模组的核心需求是什么?
- 宽带性能:需在3.3-6GHz频段内实现低插损(<1.2dB)、高带外抑制(7-10GHz>20dB)。
- 多模块协同:滤波器、耦合器、匹配网络需协同设计,避免相互干扰。
- 工艺限制:采用IPD(集成无源器件)工艺,需在有限面积内实现高性能。
3、AI工具(EMOptimizer®)的作用是什么?
- 快速优化:通过机器学习算法自动优化电路参数(如滤波器阶数、耦合器尺寸),缩短设计周期。
- 多目标权衡:在插损、面积、相位平衡等矛盾指标中找到最优解。
4、为什么完成设计后需要进行电磁仿真?
- 验证设计准确性:UltraEM®用于芯片级三维全波仿真,确保后仿结果与理论一致。
- 进阶任务支撑:SuperEM®可模拟天线馈电与辐射特性,实现右旋圆极化。
设计指标(基础)
1. 宽带滤波器
- 频段:3.3-6GHz
- 插损:<1.2dB
- 带外抑制:7-10GHz>20dB,1-2GHz>23dB
- 回损:>15dB
2. Hybrid 90°耦合器
- 插损:<1.5dB
- 隔离度:>20dB
- 相位不平衡:85°~95°
- 幅度不平衡:<1dB
3. 匹配网络
- S12:>-0.3dB
- S11:<-15dB
设计指标(进阶)
- 面积最小化:优化版图布局,减少IPD工艺的芯片面积。
- 整体电磁仿真:将滤波器、耦合器、匹配网络整合后进行全频段仿真,验证系统级性能。
- 圆极化天线馈电:
- 使用SuperEM®设计贴片天线馈电结构。
- 仿真验证轴比(Axial Ratio<3dB)和右旋圆极化特性。
设计流程与工具链
1. 工具链说明
| 工具名称 | 用途 | 学习资源 |
|---|---|---|
| EMOptimizer® | AI驱动的电路参数优化 | 法动科技官方教程 |
| UltraEM® | 芯片级三维电磁仿真 | 用户手册第3章 |
| FDSPICE® | 系统级电路仿真与协同优化 | 在线研讨会视频 |
| SuperEM® | 高速PCB/天线电磁仿真 | 案例库 |
2. 分步设计流程
步骤1:滤波器设计
- 拓扑选择:采用阶梯阻抗谐振器(SIR)或交指型结构,平衡带宽与尺寸。
- AI优化:输入目标频段和插损,EMOptimizer®自动生成参数组合。
- 仿真验证:UltraEM®验证带外抑制,调整谐振单元间距优化抑制特性。
步骤2:耦合器设计
- 结构设计:使用分支线耦合器或Lange耦合器,确保90°相位差。
- 幅度平衡:通过微调线宽和耦合长度减少幅度不平衡。
- 联合仿真:在FDSPICE®中与滤波器联调,优化整体匹配。
步骤3:匹配网络设计
- 拓扑生成:EMOptimizer®自动生成LC或传输线匹配网络。
- 寄生效应抑制:在UltraEM®中提取版图寄生参数,迭代优化S参数。
步骤4:版图整合与验证
- 面积优化:采用蛇形走线或3D堆叠减少布局面积。
- 全系统仿真:在UltraEM®中导入完整版图,检查端口隔离度和插损一致性。
步骤5:进阶任务实现
- 天线设计:在SuperEM®中设计微带贴片天线,调整馈电点位置实现右旋圆极化。
- 联合馈电仿真:将耦合器输出端口连接天线,仿真轴比和辐射方向图。
评分标准与策略
1. 初赛
完成基本设计要求,提供完整的设计报告即可通过初赛
- 性能指标(60分):优先满足插损、带外抑制等硬性指标,确保仿真报告完整。
- 版图质量(15分):布局需清晰标注关键模块,AI与电磁仿真结果需一致。
2.分区决赛
关于电磁仿真:初赛和分区赛要求各个无源器件独立做AI及电磁仿真即可
- 优化指标(20分):通过创新结构(如混合耦合器)或算法(如遗传算法优化)争取加分。
- 附加题(20分):右旋圆极化仿真需提供轴比图和3D辐射方向图。
3. 全国总决赛
关于电磁仿真:总决赛要求电路中的无源器件做整体的AI及电磁仿真
- 同分区决赛
Tips
- PPT要点:突出AI优化效率、电磁仿真精度、创新设计点。
- 仿真报告:包含多频点S参数曲线、版图寄生参数提取过程。
学习资源推荐
1. 基础理论
- 书籍:
- 《射频微电子学》(Razavi):射频电路设计基础。
- 《微波工程》(David M. Pozar):深入理解传输线、滤波器设计。
- 论文:
- 在IEEE TMTT等期刊上搜索相关设计的论文,重点关注宽带滤波器设计。
2. 工具实操
- EMOptimizer®:完成官方提供的“5G滤波器AI优化”示例项目。
- UltraEM®:学习如何导入GDSII版图并设置端口激励。
3. 进阶实战
- 开源项目:
- GitHub搜索“5G RF Frontend Design”,参考开源IPD设计案例。
- 在线课程:
- Coursera“RF and Millimeter-Wave Circuit Design”(侧重实际应用)。
算能杯赛题分析
赛题任务
基于算能TPU硬件设计并实现一个边缘计算架构优化的系统,包含至少一项端到端语音模型或机器视觉应用,提供完整的软硬件端到端解决方案,并且需结合AIoT生态。
http://univ.ciciec.com/nd.jsp?id=879#_jcp=1 (赛题链接)
题目解读
关键词: TPU 边缘计算 AIoT 端到端语音模型 机器视觉
1、TPU和边缘计算是什么?
TPU(Tensor Processing Unit)是专为张量运算设计的加速芯片,擅长处理深度学习中的矩阵计算,具备高算力、低功耗特性。算能TPU支持INT8/FP32等精度,适用于边缘端模型推理。
边缘计算 指在靠近数据源的设备端完成计算,而非依赖云端,可降低延迟、提高隐私性。本赛题需结合TPU算力优势,在边缘设备(如开发板、微服务器)上部署智能系统。
两者关联:TPU提供边缘端的高效算力支撑,结合AIoT设备(传感器、摄像头等)实现实时数据处理与决策。
2、赛题要求的端到端语音模型与机器视觉的应用要求是什么?
端到端语音模型 指从原始语音输入到最终输出(如文本、指令)的完整模型,需在TPU上完成推理优化。
机器视觉 需实现图像识别、目标检测等功能,例如基于YOLO、ResNet等模型的移植与加速。
特定场景的解决方案:需在应用场景(如教育、医疗)中提出独特解决方案,例如结合多模态交互(语音+视觉)或轻量化模型设计。
3、如何基于TPU硬件完成设计?
开发流程:
- 模型训练:使用PyTorch/TensorFlow等框架设计模型;
- 模型转换:通过TPU-MLIR工具链将模型转换为TPU可执行格式;
- 硬件部署:在开发板(如Milk-V Duo、Airbox)上集成模型,连接传感器/外设,完成系统联调。
设计指标(基础)
- 基于算能TPU设计一个边缘运算应用:
首先根据场景选择TPU硬件——小算力端侧处理器(如CV1800B)需高实时性,边缘算力处理器(如BM1684X)需支持多模态融合。其中价格高的的硬件设备有低竞争性的天然优势。然后基于硬件设计一个符合赛题要求的应用即可。
- 片上接口应用与扩展:
要尽可能多的使用板卡上的资源,“榨干”板卡的价值。但同时也要预留接口支持外设扩展(如摄像头、传感器),或与其他AIoT设备(如Sipeed Maixcam)联动,给予客户端充分的发挥空间。 、
设计指标(进阶)
- 算法创新:
可以优化自己的算法,也可以应用别人的算法,然后在具体应用场景进行优化。也可以针对大模型,针对任务优化模型结构(如剪枝、量化),或设计新算法(如轻量级AIGC生成),提升推理速度或准确率。
- 多模态融合:
多模态交互指在人机交互过程中,综合运用多种不同的交互方式和信息模态,以实现更加自然、高效、灵活的人机信息交流。在设计作品中应该结合语音、视觉、文本等多模态输入,设计跨模态交互系统(如教育场景的智能助教)。
- 异构协同:
利用开发板多核特性(如CV1800B的Linux+RTOS双系统),分配任务至不同核心,优化资源利用率。实际上运行大模型,本来就需要异构协同,单一个TPU无法进行任务管理。
- 商业落地:
设计具备实际应用价值的方案,例如医疗场景的病理影像实时分析系统,并提供成本与功耗评估。
评分机制
初赛
除了设计报告,初赛需要提供PPT和视频
- 方案设计(20分):场景合理性、技术原理清晰度、架构创新性。
- 系统实现(45分):硬件构建完整性、算法创新性、功能扩展性。
- 作品输出(35分):代码规范性、演示视频流畅度、现场答辩表现。
分区决赛
复赛则主要是演示效果
- 现场演示:系统需在选定硬件上实时运行,重点考核稳定性与实时性(如语音响应延迟≤200ms)。
- 性能对比:提供优化前后数据(如模型推理速度提升50%)。
全国总决赛
决赛一定要做商业计划,同时突出创新点以及创新点的实际应用成果。
- 高阶要求:需实现多模态融合或异构协同设计,并提供商业化落地潜力分析。
- 创新加分:结合AIGC(如边缘端Stable Diffusion生成)、具身智能机器人等前沿方向。
Tips:
- 若使用BM1684X+Airbox,优先探索AIGC场景(如边缘端LLM对话),易获评分倾斜。
学习路线
三步冲刺国奖 ⚡
- 第一步:掌握TPU开发基础——学习TPU-MLIR工具链,完成官方示例(如YOLOv5部署);
- 第二步:设计完整系统——选择场景(如智能机器人),实现数据采集、模型优化、硬件部署全流程;
- 第三步:突破进阶指标——尝试多模态交互(语音+视觉控制机器人),或优化模型至超越业内SOTA。
推荐资源:
奕斯伟杯赛题分析
赛题任务
基于ESWIN RISC-V架构开发板设计并实现边缘侧AI应用,并且需要结合硬件加速模块(NPU/DSP/GPU)优化性能,提供端到端解决方案。
http://univ.ciciec.com/nd.jsp?id=892#_jcp=1 (赛题链接)
题目解读
关键词: RISC-V 边缘计算 机器视觉 多模态交互 硬件加速
1、RISC-V在边缘AI中的优势是什么?
边缘计算 指在靠近数据源的设备端完成计算,而非依赖云端,可降低延迟、提高隐私性。本赛题需基于RISC-V架构优势,在边缘设备设计并实现边缘侧AI应用。RISC-V架构在边缘计算有以下优势。
- 开放性:开源指令集,灵活定制扩展,避免生态垄断。
- 低功耗高性能:适合边缘端资源受限场景,结合硬件加速模块(NPU/DSP)提升AI算力。
- 高安全性:架构可控,适合工业检测、自动驾驶等对安全要求高的场景。
2、赛题核心要求是什么?
核心需求其实就是在一个创新的场景下做一个板卡应用,然后该应用要用到板子上的硬件加速单元
- 场景创新:需在缺陷检测、智慧交通、机器人控制等方向提出新应用,结合图像/视频信号处理。
- 硬件加速:必须利用开发板内嵌的NPU(20 TOPS INT8)、GPU、DSP等模块优化算法性能。
- 多模态扩展:进阶需融合语音、文本交互,提升系统智能化水平(如语音控制机械臂)。
3、如何选择开发板?
HiFive Premier P550与ESWIN EIC7700-02-1154B1功能完全一致,仅商标和颜色不同。
- 关键硬件资源:
- 四核RISC-V CPU(1.4GHz~1.8GHz) + 20 TOPS NPU + 8K视频编解码。
- 外设支持:PCIe、USB 3.2、HDMI、SATA等,可扩展摄像头、传感器、屏幕。
设计指标(基础)
- 基于赛题提供的软硬件做一个场景适配的AI应用:
选择工业检测/智慧交通等场景,设计完整的图像采集→处理→决策流程(如YOLOv8目标检测)。软件系统需要基于开发软件包(包括OS、ESWIN EIC7700X SDK等)实现完整的软件功能。软件功能需要覆盖机器视觉新应用及新算法,基于对硬件平台的正确理解,使用相关开发环境(包括操作系统以及深度学习开发套件)有效实现上层功能。
- 在片上实现硬件加速功能:
首先要明白硬件加速的概念,软件加速是通过代码优化达到系统运行效率提升,而硬件加速则顾名思义是通过硬件优化达到系统运行效率提升。举个例子,当我们的系统运算包含大量的矩阵运算,只用CPU来算太慢了,严重影响了系统效率。此时我们可以增加一块TPU(张量处理单元-擅长矩阵运算)并矩阵运算的部分调整到TPU上运行,这样整体的运行效率就提升了,这就是硬件加速。赛题提供的板卡,片上包含了NPU、GPU、DSP等处理单元,我们可以通过SDK调用NPU/DSP加速模型推理(如ResNet量化部署),对比纯CPU性能提升≥50%。
- 系统完整性:
需要完成完整的系统设计,并且设计报告中需要提供硬件连线图(摄像头连接PCIe)、软件流程图(模型编译→推理→结果输出)、关键代码(SDK接口调用)。算法需说明训练/量化过程,提供准确率、FPS等验证数据。
设计指标(进阶)
- 多模态交互:
首先什么是多模态交互?多模态交互指在人机交互过程中,综合运用多种不同的交互方式和信息模态,以实现更加自然、高效、灵活的人机信息交流。这个很好理解,我们可以举以下两个例子。
- 语音+视觉:例如语音指令控制机械臂抓取识别到的目标。
- 文本+视觉:结合OCR技术提取图像中的文字信息(如交通标志识别)。
- 硬件算子优化:
首先什么是算子优化?算子是指在数学、计算机科学和工程领域中,对数据进行特定操作的基本运算单元。在线性代数中,我们就学过一些微分、积分、梯度运算算子。在硬件层面,算子通常由电路实现,例如加法器、乘法器、卷积核等。硬件算子优化就是通过对这些实现算子的硬件电路或硬件架构进行改进,以提高算子的执行效率、降低能耗等。在赛题中,主要可以通过GPU、DSP、NPU相关的优化工作。
- 基于GPU/DSP开发自定义算子(如非极大值抑制NMS加速),减少延迟。
- 结合NPU实现混合精度推理(INT8+FP16),平衡速度与精度。
- 商业化扩展:
这一拓展主要针对确实有不错市场应用前景的设计,评估系统成本与功耗,设计可量产方案(如工业缺陷检测机)。在完成前面设计的基础上,可以尝试去做一下。
Tips:
- 硬件限制:NPU仅支持特定算子(如Conv2D、ReLU),需提前验证模型兼容性。
- 多模态陷阱:语音交互需考虑环境噪声抑制,推荐使用端到端模型(如Wav2Vec 2.0量化版)。
推荐资源:
评分机制
初赛
初赛还是以文档内容为主,要好好些文档,写好的文档给老师师兄看看修改优化,同时视频要好好剪辑(可以有礼貌地拜托宣传部的同学)。
- 方案设计(20分):场景创新性(10分)、硬件加速合理性(10分)。
- 方案实现(45分):功能完整性(25分)、工具链使用规范性(10分)、硬件优化深度(10分)。
- 作品输出(35分):演示视频流畅度(10分)、文档质量(10分)、答辩表现(10分)。
分区决赛
复赛的核心在于硬件加速,现场需要演示硬件加速的优化成果。
- 现场演示:需在开发板上实时运行,重点考核延迟(如目标检测≤100ms)与稳定性(连续运行1小时无宕机)。
- 性能对比:提供硬件加速前后数据(如NPU推理速度提升3倍)。
全国总决赛
决赛则高阶要求必须要二选一实现,并且需要提供商业落地报告。
- 高阶要求:必须实现多模态交互或自定义硬件加速算子,提供商业化落地分析报告。
- 创新加分:结合大语言模型(如边缘端Llama 2精简版)实现语义理解功能。
学习路线
四步冲击国奖 🚀
- 第一步:熟悉开发板——完成官方Demo部署(如YOLOv5缺陷检测),掌握SDK调用与模型量化流程。
- 第二步:设计基础系统——选择场景(如智慧交通车辆计数),实现摄像头数据采集→模型推理→结果可视化全流程。
- 第三步:优化性能——利用NPU加速模型,对比CPU/GPU/NPU的FPS与功耗,撰写优化报告。
- 第四步:突破进阶——添加语音控制模块(如ESP32麦克风+语音识别模型),实现多模态交互。
中科亿海微杯赛题分析
赛题任务
在中科亿海微的FPGA板卡上建立视频流,并完成至少一项基于识别的图像处理应用
http://univ.ciciec.com/nd.jsp?id=889#_jcp=1 (赛题链接)

题目解读
关键词: 目标检测 图像处理 FPGA 视频流 AI模型
1、什么是视频流?如何在FPGA上建立视频流?
视频流就是指一个连续的视频图像从输入到输出的整个过程,可以抽象成A端口输入视频数据,B端口输出视频数据这么一个模型。 在FPGA上举个视频流例子,比如我们可以通过一个OV5460摄像头采集图像,然后通过DVP接口传入FPGA,接着通过FPGA之后从HDMI接口输出到屏幕。此时摄像头+DVP接口组成了A端口,而HDMI+屏幕组成了B端口,这就完成了一个完整的视频流。而FPGA在其中承担的作用就是将DVP接口和HDMI接口衔接起来,使得视频数据能够完成闭环。
2、什么是图像处理?如何在FPGA上进行图像处理?
什么是图像处理? 广义上来说任何改动了原始输入的图像数据的操作,都属于图像处理。图像处理通常基于两个目的——要么是为了优化图像质量,要么是为了提取图像信息。比如我们常说的白平衡,锐化,色差矫正就是为了优化图像质量,边沿检测,梯度检测等就是为了提取图像信息。 如何在FPGA上进行图像处理? 聪明的你大概已经猜到了,刚刚在第一个问题里,我们提出了A端-B端的概念,第二个问题的第一问我们提出了改动原始图像数据这个概念,那么很容易猜到,在A端口到B端口的中间增加一些图像处理算法不就可以完成简单的图像处理了吗? 而A->B这一中间段在刚刚的例子里,不就是FPGA吗?整个过程其实就是将传统算法写成HDL代码,综合出电路在FPGA上,视频图像数据从A端输入进入到FPGA经过写好的算法处理输出到B端。至此你已经知道FPGA图像处理是怎么个事了。
3、如何在FPGA上实现目标识别?
刚刚的两个问题其实已经足以解答第三个问题,采集数据-A口进,加入识别算法,B口出-显示识别结果。 但是问题是,识别算法该怎么做?识别算法主要分为两种,一种是传统的模板匹配算法,另一种是AI识别算法(赛题鼓励AI识别)。这两种算法网络上都有大量的开源代码和教程,甚至有训练好的开源模型,同学们根据关键词检索,可以自行学习。
设计指标(基础)
- 在EQ6HL130板卡上建立视频流;
Link-Sea-H6A图像处理套件是中科亿海微基于自研芯片EQ6HL130开发的适用于图像处理应用开发的套件,基于该套件的硬件基础进行开发。建立视频流应该很简单,大概只需要做简单的移植工作,官网资料显示该板卡支持OV5640摄像头,通过DVP接口与FPGA实现图像的传输。意味着应该会有相应的demo。片上有VGA,HDMI,LCD接口输出支持,那么图像显示部分应该也会有相应的demo。蹲群资料,或者直接去找客服要应该是能要到的。
- 完成识别功能,识别数量尽可能多,精度尽可能高;
在建立视频流的基础上继续做图像处理,这里的硬性要求是做识别,而且对种类和精度提出了要求。可以去移植正点原子的识别demo,模板匹配的和CNN神经网络的应该都有。
设计指标(进阶)
-
设计应尽量可能使用到开发板上的外设接口;
对片上接口应用提出了要求,建立视频流已经用了两个接口了,假设使用ov5460摄像头输入hdmi输出,那么就是用了DVP和HDMI连G个接口。可以继续尝试使用其他接口,例如使用网口连接以太网实现视频导出、使用uart外接按键动态修改参数、使用多摄像头输入等方案。
-
对数据通路架构和时序进行优化设计,尽可能提高视频流帧频;
影响视频帧率的最大因素是时钟频率,要对时序设计进行优化,首先要避免时序错误,然后在此基础上尽可能地提高时钟频率。可以考虑流水线工作设计、数据缓存等方案提高架构的频率许可,以达到更高的帧率需求。
-
鼓励参赛队如使用AI模型进行识别;
鼓励队伍采用AI神经网络进行识别,而不是使用传统算法。
评分机制
具体材料见官网要求,在此只做分析总结
初赛
完成上述指标,提交工程和设计报告。其中图像处理模块设计占总分的50%,意味着非AI处理方案几乎不可能进入国赛。
分区决赛
现场演示+答辩
全国总决赛
未给出
学习路线
该赛题比较简单,四步冲击国奖 🚀
- 1是阅读板卡manual并学习软件开发平台
- 2是找demo搭建视频流
- 3是选取图像处理算法进行识别
- 4是优化时序提高帧率,国奖到手。
紫光同创赛题分析
赛题题目
基于紫光同创FPGA的创新应用系统
http://univ.ciciec.com/nd.jsp?id=888#_jcp=1(赛题链接)
赛题解读
本次紫光同创杯围绕 FPGA的应用展开,提供了三个赛题方向: -基于FPGA的机器人 -基于FPGA的远程实验室 -基于紫光同创FPGA的 IP Core开发
比较推荐方向一和方向二,资料比较多相对容易,方向三难一点。所以可能选方向一和方向二的队伍多一点,方向三的少一点,但是不知道获奖的人数是怎么分配,如果是按参赛队伍数量分配的话,选哪个获奖可能都差不多。
方向一:基于FPGA的机器人
基础
- 机器人运动控制 电机、机械臂,需要PWM模块,PID算法等。
- 传感器数据处理 温湿度传感器、红外传感器、超声波等。
- 人机交互接口 可以使用蓝牙遥控、触摸屏等。
进阶
- 低延迟高精度反馈 带力矩反馈的舵机。
- 感知与目标识别 摄像头、图像识别。
- 多机器人协作 主要是通信,可以用蓝牙,但是多机器的太烧钱了,FPGA的板太贵了(༎ຶ⌑༎ຶ)。
方向二:基于紫光同创FPGA的远程实验室
基础
- 教学基础项目的开发 完成不低于5个数字电路基础实验,如:流水灯、按键、视频显示等。
- FPGA的远程下载及代码固化 模拟JTAG,完成FPGA板卡的远程下载和固化。
进阶
- 教学高阶项目的开发 a.完成除5个基础实验以外的更多高阶实验内容,并提供完善的代码与文档;b.进行远程调试,实时抓取波形。
- 远程实验测试测量 设计示波器功能,能对远程实验系统控制的信号进行实时采集与分析。
- 数字孪生 a. 远程虚拟产生测试激励条件,并能和系统实际硬件一一对应,如远程操作按键、拨码开关等,并能将产生得到的实验现象进行回传; b. 完成远程信号发生器功能,能远程控制信号发生器产生信号并将该信号作为激励输入到实验系统; c. 通过远程摄像头(如ip camera等)实时观察实验系统运行状态,并能精准自动对焦观察实验现象。
学习方向
1、熟悉verilog语言(应该都会)。
2、熟悉fpga应用开发,掌握各种接口(IIC,SPI等)以及各种外设的应用,推荐《紫光同创FPGA权威设计指南》。
建议:在购买模块时先找资料或教程,买资料或教程比较丰富的模块,要不自己写驱动还是比较麻烦的。方向一跟往年的robei杯有点类似,参考代码。
Robei赛题分析
基于Robei EDA工具的IP设计
基于国产Robei EDA工具,从架构原码开始设计,打造安全可控的数字IP,并基于该IP进行评分。
http://univ.ciciec.com/nd.jsp?id=880#_jcp=1
赛题解读
通过Robei EDA工具设计实现一款或者多款接口IP、应用于总线上的协处理器如Codec,加速器等,甚至开发RISC-V内核IP等均可以参加比赛。要求低速IP满足APB/Wishbone总线接口,高速IP满足AXI/Wishbone接口协议。
关键点:IP 总线 功能模块
是什么?
IP核:工业级的可复用组件,在这里称之为IP核的话,设计的时候需要注意其稳定性验证、接口完备、文档规范。
**通信总线:**总线协议是一组规则和标准,用于在计算机系统或嵌入式系统中的不同硬件设备之间进行数据通信,典型应用为IIC、SPI等。
| 总线类型 | 典型应用场景 | 关键特征 |
|---|---|---|
| APB | 低速低功耗外设控制 | 2-phase传输,无流水线 |
| AXI | 高性能数据传输 | 5通道分离,支持乱序执行 |
| Wishbone | 开源SoC | 支持多种拓扑结构 |
**功能模块:**模块在收到指令后根据==寄存器配置和数据==执行的一系列操作,如通过编码译码、调制解调等完成音频调制和电机控制等。
怎么做?
细读题目我们发现,设计的IP核需要同时满足两个核心要素:总线接口部分与功能接口部分。
即内部实现需包含的基本要素如下:
简单的总线协议解析逻辑(APB/AXI状态机)
要求能够实现IP与SoC系统间的标准化通信,包括以下基本设计要点:
| 协议合规性 | 遵循时序和信号规范,如AXI协议中VALID/READY握手信号的同步机制。 |
| 状态机设计 | 三段式状态机划分APB的IDLE、SETUP、ACCESS三态转换。 |
| 译码机制 | 寄存器状态映射寻址地址的策略 |
| 错误处理 | 在程序卡飞的时候可以自动复位 |
功能接口模块
要求实现特定领域的功能,可以选择的方向有:
| 计算型 | 视频编解码/神经网络推理 |
| 控制型 | 电机驱动/PWM波形生成 |
| 接口型 | 传感器数据融合/无线协议转换 |
在设计时同样需要注意功能在算法上的实现(并行结构)、数据流的处理、状态机的使用以及异常状态的处理。
配置寄存器组(设置功能参数)
在IP核的外部和内部要求提供灵活可控的用户接口,基本需要包括以下:
| 控制寄存器 | 启停控制/工作模式选择 |
| 参数寄存器 | 设置算法系数/阈值参数 |
| 状态寄存器 | 返回处理进度/错误代码 |
| 数据缓冲区 | 输入输出数据暂存区 |
高手在完成上述基本设计后可以尝试进行一些功能上的优化增强鲁棒性**==(队伍特色,不一定要有用但是可以吹牛逼)==**,如地址译码模块应支持动态映射策略,通过参数化配置适应不同系统的地址空间布局,同时实现多设备环境下的精准寻址;将32位寄存器划分为多个功能域,支持位级读写掩码操作(参考子网掩码);数据通路设计引入乒乓缓冲区消除处理瓶颈。
大家可以发挥想象力自由发挥,这点能抓住现场老师的话还是挺加分的,前提是基本功能的正常实现
以上内容在设计文档中需要详细叙述。
==选题参考:一个能够支持APB总线的高端智能机器人控制IP核== 可以选择自己擅长的应用领域来构建类似的IP结构。
赛题任务要点
初赛
完成度要求不高,能够通过RobeiEDA实现IP的仿真即可,题目允许多设计配套使用的几个IP
设计文档的撰写注意规范和格式,可以多多参考企业公布的技术文档或使用手册
工程文件代码和命名等整理得规范一些
PPT在保证内容易懂结构清晰的时候可以适当美化
视频可以多拍几遍,注意效果的呈现,讲解内容的语气语调
初赛提交材料:IP设计文档、PPT介绍、IP工程文件、5分钟讲解视频。
分区赛
需要使用初赛设计的IP核在Robei八角板上进行功能验证与演示
在比赛前要提前演练一下演示流程,把握时间
提前准备一下评委可能会问的问题,挑重点
PPT在保证内容易懂结构清晰的时候可以适当美化
提前考虑比赛出现的各种情况,现场的管理可能不会特别规范
要求:对IP进行PPT演示(5分钟)、板级演示(3分钟)、问题回答(2分钟)。
国赛
把设计出来的IP应用到针对自身特定应用场景的设备雏形。同时重点发掘IP在实际应用中遇到的问题,并对其修正提升
除了FPGA开发IP核之外还需要其他外设的使用,发挥想象力和钞能力,能进到国赛的话其他人很可能会更卷
提前考虑比赛出现的各种情况,现场的管理可能不会特别规范
要求:PPT演示(5分钟)、实物演示(5分钟)、问题回答(5分钟)。
推荐学习路线与分工
RobeiEDA不好用,很难用,大家在开发过程中使用Vivado开发和验证再在最后移植到RobeiEDA上实现功能即可.
把Verilog基础打好后先学总线协议的使用和开发,能够有一个能够熟练调用和修改的总线协议模块,随后确定自己小组的设计目标,通过一个或一组IP核能够实现怎样的功能,然后在网上找一个相似项目进行修改,或者通过现有模块来重构成一个新的项目,备赛过程中注意协作。
三个人可以每个人负责IP核中不同的模块经过测试之后没问题后整合到一起,文档和PPT最好可以有一个人来专门负责(不是说全部一个人写)。
重点处理跨域协同问题,时钟域交叉处理推荐使用异步FIFO进行数据同步,兼容性设计可通过总线封装层实现,例如设计AXI4-Lite到AXI3的协议转换接口。验证阶段可以进行全系统高压测试,模拟多主设备并发访问场景,确保IP核在复杂环境下的稳定运行。这些可以作为一些亮点
第九届信诺达杯赛题分析
赛题任务
基于ST3020集成电路测试系统,设计C语言测试程序,完成UC2625无刷直流电机驱动芯片的功能测试与参数测量,涵盖初赛方案设计、分赛区PCB接口板开发及全国总决赛现场测试任务。
http://univ.ciciec.com/nd.jsp?id=889#_jcp=1 (赛题链接)
赛题解读
核心挑战
UC2625为数模混合芯片,需同时处理数字信号(PWM控制)与模拟信号(电流检测、电压调节),测试需兼顾:
- 数字资源与模拟资源的协同调用:ST3020测试系统需同时生成数字激励(如PWM波形)并采集模拟响应(如电流/电压值)。
- 接口板设计复杂度:PCB需兼容数字信号(逻辑输入)与模拟信号(误差放大器输出),需避免信号串扰。
UC2625关键功能
- 电机驱动控制:通过PWM调节电机转速。
- 保护机制:过压保护(OV)、电流检测(ISENSE)、故障诊断(Error Amp)。
必测参数整理
| 参数类别 | 具体参数 |
|---|---|
| 电源特性 | 供电电流、VCC关断阈值 |
| 逻辑输入 | 所有输入引脚逻辑电平兼容性 |
| PWM与误差放大器 | 误差放大器电压增益、PWM幅值 |
| 电流检测 | 峰值电流阈值、ISENSE偏移电流 |
| 低边驱动 | 高电平输出(1mA/50mA)、低电平输出 |
| 高边驱动 | 低电平输出(1mA/50mA) |
| 参考电压 | 输出电压、线性调整率、短路电流 |
注:具体测试条件与限值以UC2625芯片手册为准。
评分机制
初赛(方案设计)
- 核心要求:提交包含功能测试与所有必测参数的测试方案(格式参考学术论文)。
- 加分项:添加1-2个选测参数(需手册明确标定上下限)。
分赛区决赛(软硬件实现)
- 硬件:自主设计并焊接PCB接口板,需兼容数模信号。
- 答辩:阐述测试原理与方案设计,可弥补硬件/方案瑕疵。
全国总决赛(现场测试)
- 限时挑战:2小时内完成未知芯片的测试程序开发(官方提供接口板与数据手册)。
- 评分权重:现场测试成绩占70%,答辩占30%。
学习路线
初赛阶段
- C语言基础:
- 掌握函数调用、指针操作,能理解ST3020官方例程。
- 推荐资源:菜鸟教程C语言。
- ST3020系统手册:
- 重点学习数字图形文件编写、模拟资源调用函数(如
set_voltage())。
- 重点学习数字图形文件编写、模拟资源调用函数(如
- UC2625芯片手册:
- 精读引脚定义、典型应用电路、参数测试条件。
分赛区决赛阶段
- PCB设计:
- 使用嘉立创EDA完成接口板设计,注意数模分区布局。
- 推荐工具:嘉立创EDA。
- 焊接实操:
- 练习0402封装焊接,确保信号通路可靠性。
全国总决赛阶段
- ST3020强化训练:
- 熟练使用
test_sequence()函数实现自动化测试流程。
- 熟练使用
- 英语速成:
- 重点掌握芯片手册中的术语(如"Hysteresis"、"Line Regulation")。
推荐资源
总结:本赛题是“软硬结合”的实战挑战,需打通C语言编程、硬件接口设计、芯片测试原理三大环节。初赛阶段需深度吃透芯片手册,决赛阶段则依赖快速工程化能力与临场应变。