中科芯杯赛题分析
赛题任务
设计一个TPU(Tensor Processing Unit),并且在FPGA上进行验证。
http://univ.ciciec.com/nd.jsp?id=886#_jcp=1 (赛题链接)
题目解读
关键词: TPU AXI FPGA
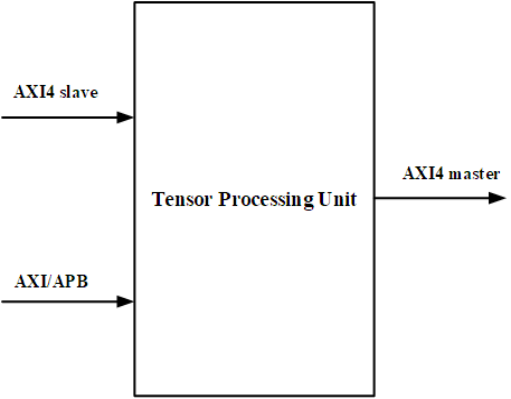
通过上图,我们可以很清晰地看到我们需要设计的模块。其中输入有AXI4 slave,AXI/APB;输出有AXI master。还有中间进行计算的TPU。
TPU
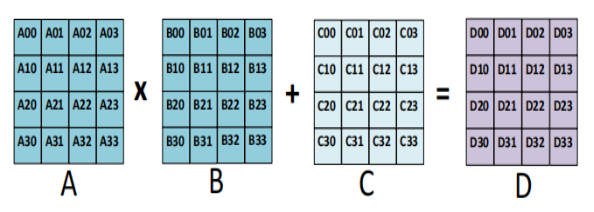
我们要设计的TPU需要实现矩阵乘加计算,支持INT4、INT8、FP16、FP32四种数据精度,支持混合精度计算。并且要对不同精度的乘法运算有硬件资源复用设计(举个例子:一个16位宽的支持 INT8 和 INT16 的乘法单元,那么做INT8运算时,前8位全是0)。可以参考谷歌的TPU设计以及AIC2021 Project1实现了一个简单的TPU。
总线
总线是用来传输数据的,比如你手机通过数据线传输数据到电脑,那么你的数据线就是总线。有了总线,就得定义手机跟电脑应该怎么沟通,手机是发送数据给电脑,还是电脑发射数据给手机,该发送什么数据,这些就是总线协议定义的。 我们一般称主动发起通信的模块为master(主设备), 称响应通信的模块为slave(从设备)。外部模块,比如CPU作为master,发送要计算的矩阵到TPU的AXI4 slave, 并且通过AXI/APB配置TPU的寄存器。TPU完成计算之后,通过AXI4 master将计算完成的数据发送出去。我们所要设计的模块,要求使用的协议是AXI4-full与APB。前者用于读取与写回矩阵数据。后者用来配置寄存器(可能用于指定要进行的计算类型,题目中指定由参赛队伍自行定义)。
FPGA验证
FPGA验证在题目中是附加分,但是要完成还是比较简单。 这里提供一个简单的验证方案。电脑通过串口将矩阵发送到FPGA,FPGA接收完成数据之后,写一个模块,将要计算矩阵数据写入你设计的TPU,计算完成后,写一个模块,该模块接收TPU的AXI4 master发来的数据,再通过串口写回电脑。 电脑接收完成数据,可以再通过python或其他软件去计算发送过去的矩阵,验证接收到的计算结果是否跟电脑的计算结果相同。
设计指标(基础分)
- 实现要求的功能
m16n16k16、m32n8k16、m8n32k16的矩阵乘加运算,INT4、INT8、FP16、FP32数据格式,混合精度计算模式,支持计算结果溢出的情况。
- 硬件资源复用方案
- 设计的综合频率、面积、功耗、理论算力值等
对于设计的频率,可以查看FPGA给出的时序分析。或者使用yosys-sta跑出来的频率与面积。
设计指标(附加分)
- FPGA验证
前文已经提到了一个简单的方案。
- 数据精度混合计算模式扩展
例如在FP16 Mixed Precision模式下,以FP16数据精度进行乘法运算,以FP32数据精度进行累加运算
- 稀疏张量计算扩展
评分机制
初赛,分赛区决赛,全国总决赛要求基本相同。但在初赛阶段不考察加分项内容;分区决赛阶段的评分仅加入一项加分项的考察评分;总决赛阶段的评分可加入两项加分项的考察评分。
开发环境
介绍两种开发环境
FPGA
可以使用Vivado,方便后续直接进行FPGA验证。使用SystemVerilog进行仿真。支持Windows和Linux。缺点就是Vivado下载完占用超过了100G
Verilator
使用vscode,Verilator,gtkwave/suffer在Linux下进行开发。仿真可以使用C++,比较灵活。占用存储空间极小。缺点是Linux学习成本高,并且做FPGA验证时还是得用Vivado。
参考资料
-
脉动阵列
这是用来计算矩阵乘法一个架构,也是Google TPU和AIC2021 Project1中采用的。里面的参考文献也推荐阅读。 -
An in-depth look at Google’s first Tensor Processing Unit (TPU)
-
In-Datacenter Performance Analysis of a Tensor Processing Unit
学习路线
- 学习数电与Verilog以及Verilog的仿真
- 总线协议,学习怎么跟你的TPU沟通。可以查看参考资料中的两个初步了解(实现总线协议需要阅读对应协议的手册)。
- 你需要点数学基础,包括线性代数。
- 学习TPU的架构,脉动阵列;最后动手写出你的第一个TPU。